
Procure-to-Pay
Having trouble controlling your procurement spend? You’re not alone.
Many organizations struggle with poor procurement spend visibility or lack it completely. Think about the old adage, “you can’t control what you can’t measure,” and you’ll realize that this is an ongoing challenge with large enterprise organizations. Without visibility into what your organization is spending, you have no way to control it.
The top, and the most obvious, reason why most organizations struggle with spend management and compliance is that the majority of procurement spend data (the way it exists today) – to put it bluntly – sucks. It’s imperfect and cannot be used.
What I mean by spend data being imperfect is that it is missing fields, is poorly attributed, has only high-level information, or in some cases, the requisite fields don’t exist at all. That makes it nearly impossible to analyze and get any actionable spend insights.
One major cause of imperfect data is that there is inconsistency across various data sources because it’s scattered across regions, ERPs, and business units. Another factor that leads to this issue is that widely-used ERPs and procurement systems were never designed to address spend data fidelity. But most importantly, what I’ve observed is that procurement departments (especially when it comes to indirect spend) are either underfunded or lack the right processes, expertise, and tools to address it effectively.
When it comes to addressing spend leakage and finding savings, it’s important to move fast.
So, how do you get to operable data? What will it really take to achieve accurate and actionable insights in order to keep your procurement spend in check? Here are my three favorite ways:
Fix spend categorization
Most organizations categorize their procurement spend based on UNSPSC (United Nations Standard Products and Services Code). Sounds useful, right? Not quite. While this is better than no classification at all, this type of approach is mostly ineffective because this taxonomy is approximate and unable to capture the sourcing view of what category managers need to take action.
Another common mistake is using your internal commodity structures or general ledger (GL) coding to categorize your spend. Your IT team helped you get purchase order history and you’re thrilled! Well, guess what? Because sourcing is done outside the building, it needs to have a flexible taxonomy aligned with supply markets – not your internal commodity structures.
If your categorization doesn’t empower you to act on it, what good is it? Your foundation is shaky and anything you do with your spend data downstream will eventually snowball – taking you further and further away from being able to control your spend. Ensure you have a flexible categorization taxonomy and fix it first.
Related: It all starts with your procurement data
Invest in data enrichment
So, you fixed your data acquisition process and implemented the right categorization structure. Now what? It’s like going to the doctor for a health checkup, but then forgetting to keep yourself healthy by eating well and exercising. What you need is ongoing data enrichment to fix the imperfect gaps and keep your data healthy. It’s like a trainer who is on a constant watch to ensure your data has the right balance of attributes.
But when it comes to categorization, most spend data is categorized at the supplier level with limited or no line-level or attribute-level information. Why is this? The reason is that procurement teams and vendors don’t have the expertise, and/or it takes too long and it costs too much to achieve the next level of granularity. As a result, it’s left unattended and you’re unable to catch spend leakage proliferating within your organization.
Let me share an example to illustrate this point. You learn that you have three suppliers across four manufacturing plant locations, and you have no idea if they are all supplying the same type of industrial protective gloves. Even worse, they might be supplying the same gloves at different prices. Now, how would you fix that?
Basic supplier-level categorization will never be able to catch such leakage. This can only be addressed by investing in line-level and ongoing data enrichment.
Drive speed to value
It’s commonly known that speed is an important competitive differentiator in the market. The notion that your business is as good as your supply chain is also pervasive. However, most enterprise organizations and vendors take months and months to get to the source of truth when it comes to procurement spend. And some never get there at all.
Here’s another example: a typical large enterprise may have well over 500,000 lines of purchase order spend data, and let’s say, conservatively, about 50% of that is imperfect. A data analyst takes roughly 10 hours to enrich 300 lines of data (at a rate of about 30 lines per hour). So, to process and enrich those 250,000 lines of imperfect data, you’ll need about 8,333 hours of effort. That would take a dedicated team of 4 data analysts almost 12 months, or almost 48 data analysts one month to solve this. Neither of these options is practical or cost-effective.
250,000 lines of imperfect data/30 lines per hour/1 analyst=8,333 hours of effort
If it takes you any longer than a month to enrich your data, your business has already moved on and you are continuously playing catch-up with limited to no value.
The takeaway
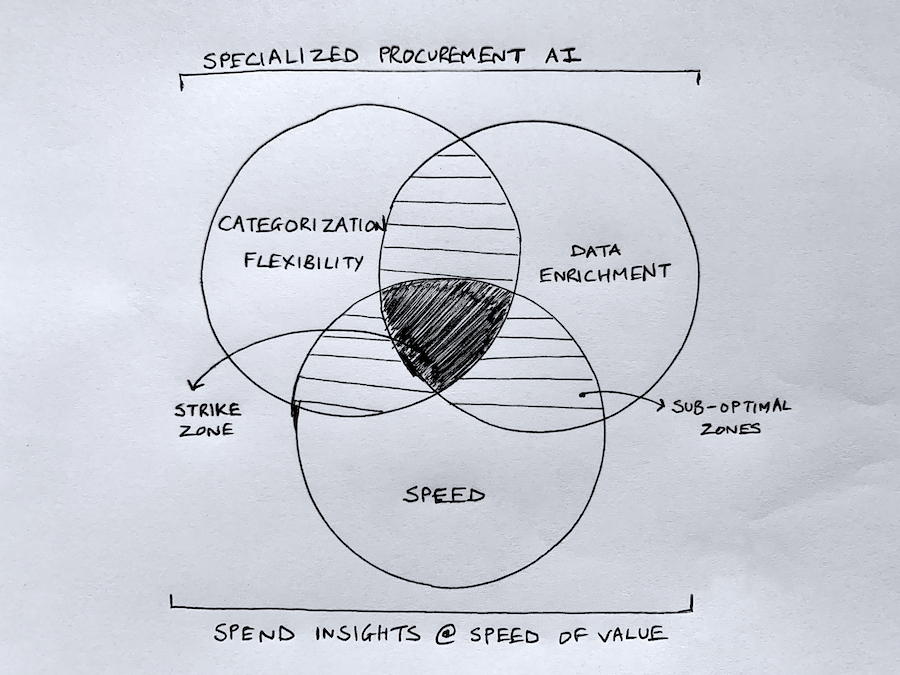
It’s hard to get away from imperfect data, but it shouldn’t be that hard to tackle it head-on. Most procurement organizations and vendors are NOT set up to solve for a combination of categorization flexibility, data enrichment, and speed. In fact, many industry professionals focus solely on spend visualization and analytics. They keep falling trap to the garbage in, garbage out data problem, and never achieve the full potential of accurate and timely spend insights.
For improved bottom-line savings, it’s crucial to focus on getting categorization data quality right. This is the foundation, and without it, your problems will just continue to snowball. It’s also important to ensure you’re focused on continuous enrichment, or your data will erode over time. And finally, when it comes to addressing spend leakage and finding savings, it’s important to move fast. People alone can’t get you there – at least not on an ongoing basis and at scale.
Leveraging a specialized procurement AI solution that addresses all three aspects is key, with a huge emphasis on accuracy and speed. This will not just empower you to get your spend under control but it will also get you a well-deserved seat at the proverbial (strategic) procurement table.
Contact Xeeva today to learn more about how to improve your imperfect data & gain better visibility into your spend!